Memcached介绍
Memcached是一个自由开源的,高性能,分布式内存对象缓存系统.
Memcached特性
基于C/S架构,协议简单
服务端启用memcached进程, 客户端可以通过telnet操作, 也可以通过各种编程语言实现的客户端存储数据及查询状态. 客户端和服务端采用的协议简单, 支持文本协议或二进制协议
基于libevent事件处理
libevent是一套跨平台事件处理接口的封装,兼容Windows/Linux/BSD/Solaris等操作系统, 封装了的接口包括poll、select(Windows)、epoll(Linux)、 kqueue(BSD), /dev/poll(Solaris)
Memcached使用libevent来进行网络并发连接的处理, 能够保证在很大并发情况下, 仍旧能够保持快速的响应能力.
libevent: http://www.monkey.org/~provos/libevent/
基于内存存储方式
为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重启memcached、重启操作系统会导致全部数据消失。另外,内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。memcached本身是为缓存而设计的服务器,因此并没有过多考虑数据的永久性问题。
基于客户端的分布式
Memcached尽管是“分布式”缓存服务器, 但其服务端并没有分布式功能, 各个Memcached实例不会互相通信以共享信息, 它的分布式主要是通过客户端实现的.
Memcached安装部署
下载安装
1 | $ sudo yum install libevent libevent-devel |
启动进程
1 | # 这里显示了调试信息, 监听TCP端口11211 最大内存使用量为64M. |
后台启动
1 | $ /usr/local/bin/memcached -p 11211 -m 64m -d |
参数说明
-p: 使用的TCP端口。默认为11211-m: 最大内存大小。默认为64M-vv: 用very vrebose模式启动,调试信息和错误输出到控制台-d: 作为daemon在后台启动
更多命令可以通过-h查看
1 | $ /usr/local/bin/memcached -h |
Memcached内存分配
Memcached默认情况下采用了名为Slab Allocator的机制分配、管理内存。在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached进程本身还慢。Slab Allocator就是为解决该问题而诞生的。
Slab Allocator基本原理
Slab Allocator的基本原理是按照预先规定的大小,将分配的内存以page为单位,默认情况下一个page是1M,可以通过-I参数在启动时指定,分割成各种尺寸的块(chunk), 并把尺寸相同的块分成组(chunk的集合),如果需要申请内存时,memcached会划分出一个新的page并分配给需要的slab区域。page一旦被分配在重启前不会被回收或者重新分配,以解决内存碎片问题。
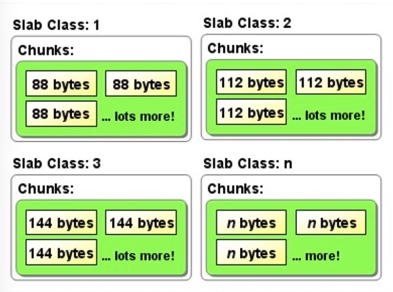
说明:
Page: 分配给Slab的内存空间,默认是1MB。分配给Slab之后根据slab的大小切分成chunk。
Chunk: 用于缓存记录的内存空间(chunk中不仅仅存放缓存对象的value,而且保存了缓存对象的key,expire time, flag等详细信息)。
Slab Class: 特定大小的chunk的组
Memcached并不是将所有大小的数据都放在一起的,而是预先将数据空间划分为一系列slabs,每个slab只负责一定范围内的数据存储。memcached根据收到的数据的大小,选择最适合数据大小的slab。memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。

Slab Allocator的缺点
Slab Allocator解决了当初的内存碎片问题,但新的机制也给memcached带来了新的问题,由于分配的是特定长度的内存,因此无法有效利用分配的内存。 例如,将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费了。
Growth Factor调优控制
memcached在启动时指定Growth Factor因子(通过-f选项),就可以在某种程度上控制slab之间的差异。默认值为1.25。 但是,在该选项出现之前,这个因子曾经固定为2,称为“powers of 2”策略.
让我们用以前的设置,以verbose模式启动memcached试试看:
1 | $ memcached -f 2 -vv |
可见从128字节的组开始,组的大小依次增大为原来的2倍。这样设置的问题是,slab之间的差别比较大,有些情况下就相当浪费内存.
来看看现在的默认设置(f=1.25)时的输出(篇幅所限,这里只写到第10组)
1 | slab class 1: chunk size 88 perslab 11915 |
Memcached过期机制
Memcached有两种过期机制: Lazy Expiration 和 LRU
惰性过期(Lazy Expiration): memcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过
最近最少使用(LRU): 当memcached的内存空间不足时(无法从slab class 获取到新的空间时),就从最近未被使用的记录中搜索,并将其空间分配给新的记录。
不过,有些情况下LRU机制反倒会造成麻烦。memcached启动时通过“-M”参数可以禁止LRU.
1 | # 小写的“-m”选项是用来指定最大内存大小的。不指定具体数值则使用默认值64MB |
客户端一致性Hash
Memcached的分布式是通过客户端Consistent Hashing(一致性Hash)算法实现的, 如下所示:
首先求出memcached服务器(节点)的哈希值, 并将其配置到0~2SUP(32)的圆(continuum)上。 然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。 如果超过2SUP(32)仍然找不到服务器,就会保存到第一台memcached服务器上。
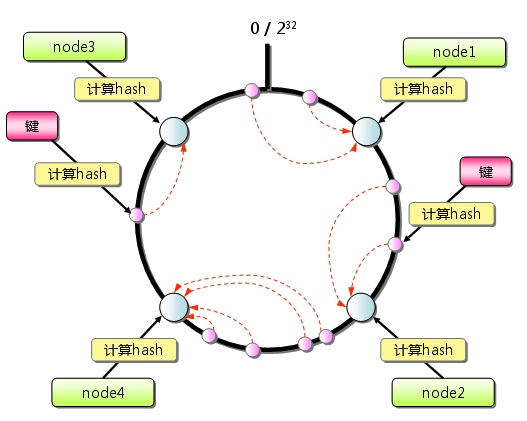
从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化 而影响缓存的命中率,但Consistent Hashing中,只有在continuum上增加服务器的地点逆时针方向的 第一台服务器上的键会受到影响.

因此,Consistent Hashing最大限度地抑制了键的重新分布。 而且,有的Consistent Hashing的实现方法还采用了虚拟节点的思想。 使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。 因此,使用虚拟节点的思想,为每个物理节点(服务器) 在continuum上分配100~200个点。这样就能抑制分布不均匀, 最大限度地减小服务器增减时的缓存重新分布。
通过下文中介绍的使用Consistent Hashing算法的memcached客户端函数库进行测试的结果是, 由服务器台数(n)和增加的服务器台数(m)计算增加服务器后的命中率计算公式如下:
1 | (1 - n/(n+m)) * 100 |
Memcached客户端
